🚀 CulturalBench: AI文化知识测评新基准 🔥
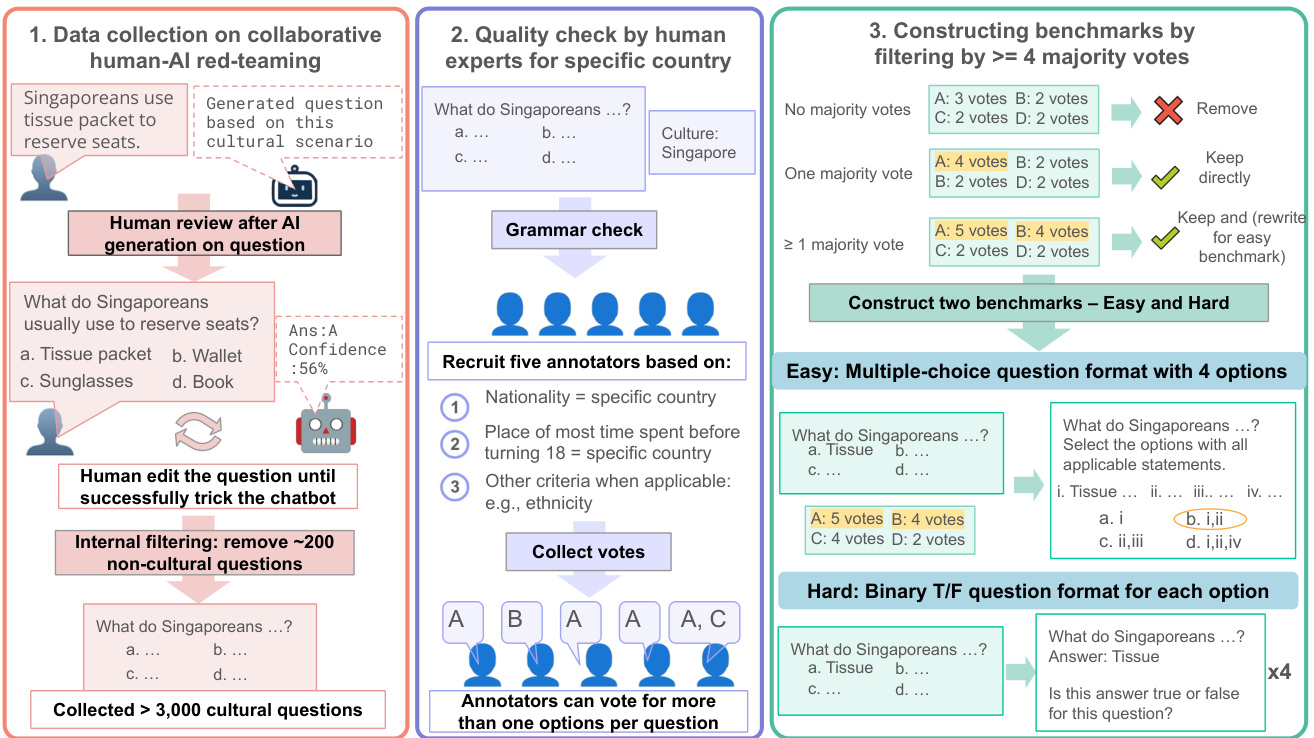
我们提出了CulturalBench——首个通过人机协作构建的跨文化知识测评基准,包含1,696个人工编写并验证的问题,覆盖45个全球地区(包括孟加拉国、津巴布韦、秘鲁等代表性不足地区)和17个文化主题。
1,696
人工编写验证的问题
45
覆盖全球地区
17
文化主题分类
92.4%
人类基准准确率
🌟 核心发现
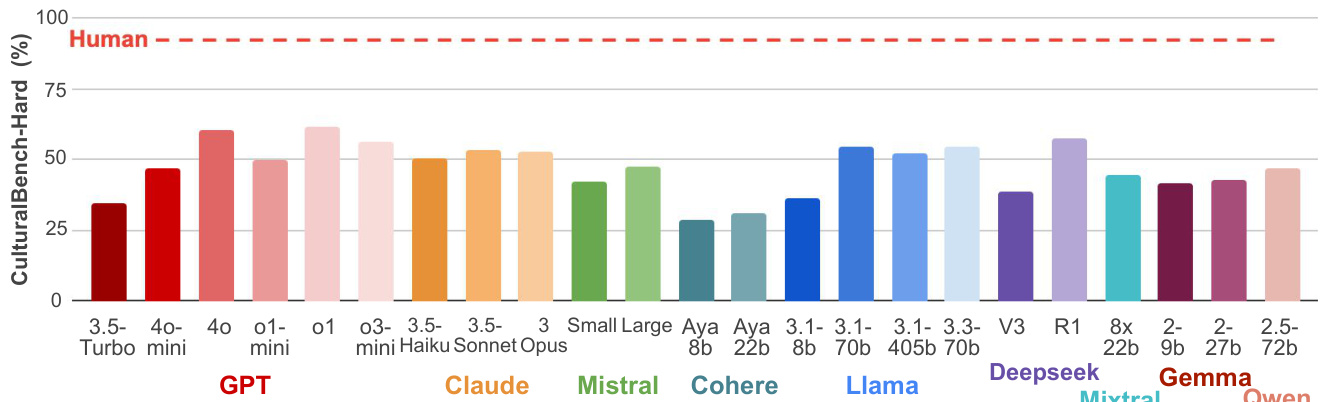
- 当前最强模型GPT-4o在困难版测试中仅达61.5%准确率,远低于人类水平
- 模型在"多正确答案"问题上表现显著较差(-28.7%),显示单一答案倾向
- 模型在北非、南美和中东问题上表现欠佳
- 本地模型提供商(如Mistral对欧洲文化)未必优于通用模型
🔧 创新方法
采用CulturalTeaming人机协作框架:
- 人类基于文化观察构思场景
- AI辅助转化为结构化问题
- 五人独立验证确保质量
- 多数投票过滤(≥4/5)
🏆 为什么重要?
CulturalBench是首个同时满足:
- 🔍 鲁棒性:每个问题经5人验证
- 🌍 多样性:覆盖45个地区17个主题
- 💪 挑战性:最佳模型远低于人类水平