我们提出了URCA框架,在生物医学研究中提取科学证据的任务上,性能比现有最佳方法提升高达10.3%!🔥 基于202个来自Cochrane系统评价的标注森林图数据集COCHRANEFOREST。

图1: COCHRANEFOREST数据集示例 - 每个研究对问题的结论标注
🌟 研究亮点
- 提出首个针对临床问题中矛盾证据的文档级科学证据提取任务
- 构建COCHRANEFOREST数据集,包含202个标注森林图、263个独特研究和923个研究问题-研究对
- 开发URCA框架,通过均匀检索、聚类增强和知识提取显著提升证据提取性能
F1分数提升
+10.3%
相比现有最佳方法
数据集规模
202森林图
来自48个系统评价
研究数量
263个
独特研究
标注对
923个
研究问题-研究对
💡 URCA框架创新点
URCA (Uniform Retrieval Clustered Augmentation) 是一个检索增强生成框架,专门设计用于解决证据提取中的独特挑战:
- 均匀检索:平衡地从多个研究论文中检索相关内容
- 聚类增强:通过语义聚类组织检索到的内容
- 知识提取:从每个聚类中提取与查询相关的信息
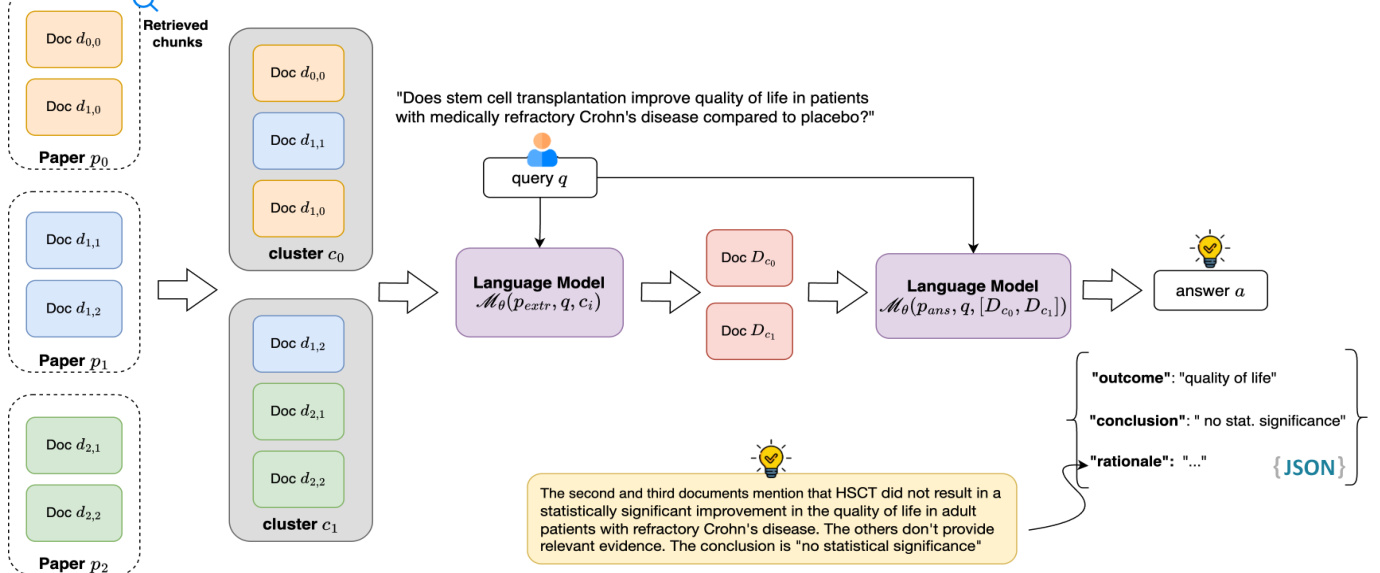
图2: URCA框架概述 - 检索、聚类和生成三阶段流程