🌟 核心发现
我们提出了一种创新方法 Diverse Chains of Thought (DCoT),通过微调使大语言模型(LLM)在单次推理中生成多样化的推理链序列。实验表明,这种方法在1.3B到70B的不同规模模型上均能提升性能,特别是在数值答案等结果空间较大的任务中效果显著。模型展现出在单次推理中自我优化初始推理链的能力,实现了以往难以达到的自我改进。
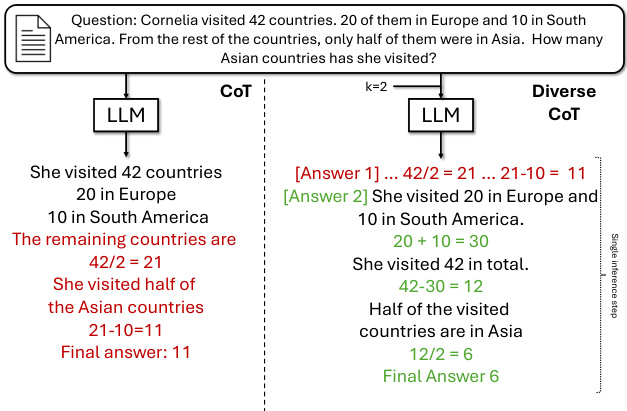
图1: DCoT方法在单次推理中生成k个推理链并选择正确答案 (k=2示例)
🚀 方法创新
首次实现LLM在单次推理中生成序列化多样推理链,无需外部反馈即可进行推理链优化
📈 性能提升
在1.3B到70B的不同规模模型上均优于传统CoT基线,数值类任务提升尤为显著
💡 自我优化
定量分析和人工评估表明,模型能在单次推理中优化初始推理链,实现自我改进
🌍 广泛适用
覆盖科学问答、数学推理、逻辑推理等多种任务类型,展现强大泛化能力
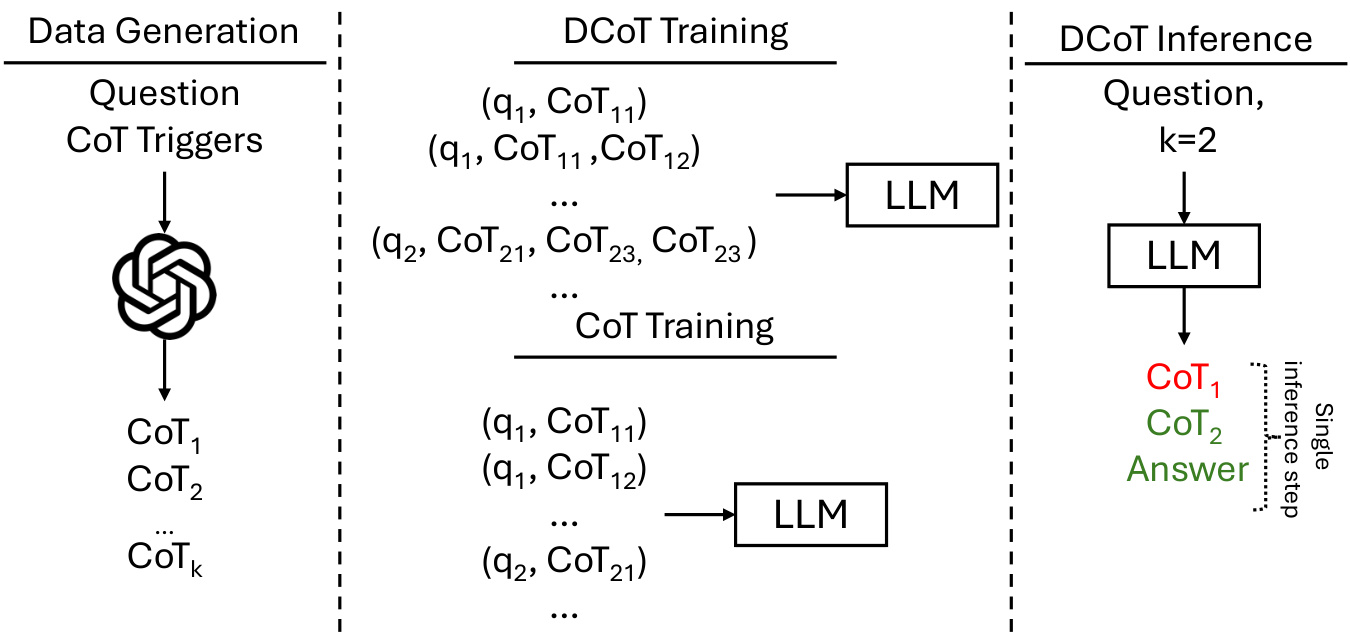
图2: DCoT训练方法 - 通过串联多个CoT进行微调,使模型学会在单次推理中生成多个推理链
🔥 关键结果
- 在Phi-1.5(1.3B)到LLaMA-2 70B的多种模型规模上均取得显著提升
- 仅需生成2个推理链(k=2)即可获得大部分性能增益,推理成本增加极小
- DCoT@1性能与CoT基线相当,可作为指令微调数据的安全替代
- 能与其他CoT扩展方法(如自一致性)协同工作,获得额外提升