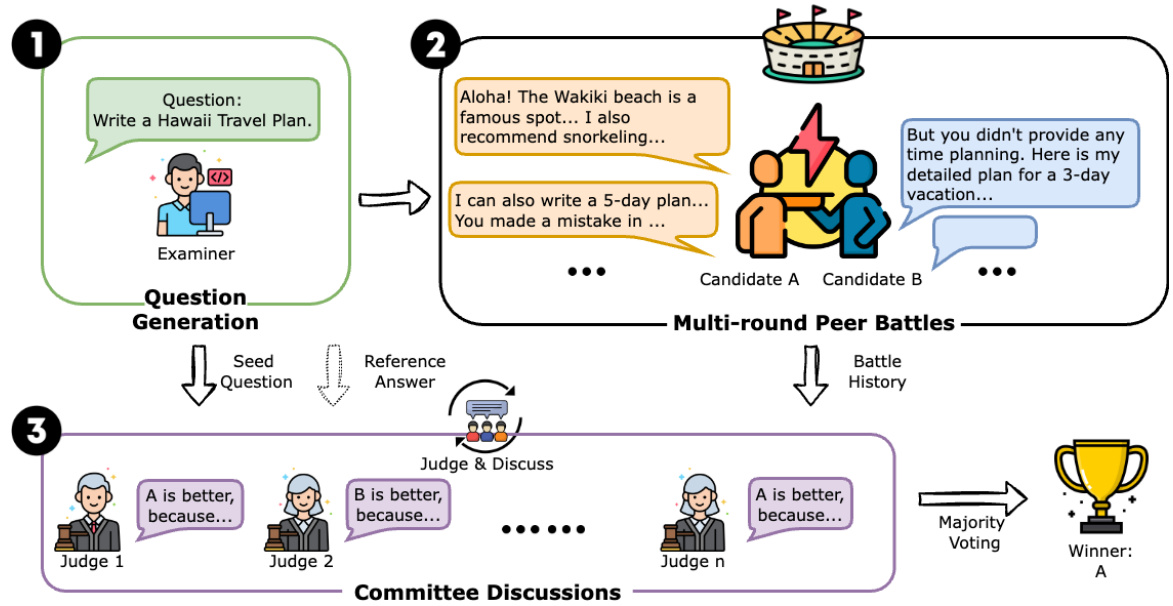
Auto-Arena框架三阶段:问题生成 → 多轮对战 → 委员会讨论
随着大语言模型(LLM)的快速发展,如何快速、可靠地评估模型性能成为关键挑战。Auto-Arena创新性地提出全自动化评估框架,通过LLM智能体模拟人类评估流程,实现与人类偏好92.14%的高相关性!
🚀 动态问题生成
由LLM考官自动生成多样化问题,覆盖写作、角色扮演、推理、数学等8大领域,避免静态数据集的污染风险
🔥 智能体对战
两个候选模型进行多轮辩论,通过批评对方弱点、提出针对性问题,充分展现模型真实能力差异
👥 委员会决策
由5个顶级LLM组成评审委员会,通过集体讨论减少单一模型偏见,提升评估公平性
92.14%
与人类偏好相关性
15
评估的最新LLM数量
0
人工标注需求
实验发现:LLM智能体在对战中展现出竞争行为和从对手学习等有趣现象,为未来研究开辟新方向!